在当今大数据时代,如何从海量数据流或静态数据集中快速、准确地找出出现频率最高的前K个项(Top K Frequent Items),是搜索引擎、推荐系统、广告投放、网络监控、实时分析等众多领域的核心需求。这一经典问题不仅考验着算法的效率,更对底层的存储支持服务提出了严峻的挑战。本文将探讨该问题的核心难点,并分析支撑其高效实现的存储与服务架构。
一、问题定义与核心挑战
问题定义:给定一个规模巨大的数据集(例如,数十亿的搜索查询词、用户点击记录、社交网络标签或日志条目),我们需要找出其中出现频率(或计数)排名前K的元素。
核心挑战:
1. 数据规模巨大(海量性):数据无法一次性装入单机内存进行处理。
2. 数据动态变化(流式性):在很多场景下,数据以高速流的形式持续到达(如Twitter推文流),需要实时或近实时地更新统计结果。
3. 查询响应要求高(实时性):系统需要能快速响应针对当前统计结果的查询请求。
4. 精确与近似的权衡:在资源受限的情况下,有时可以接受近似结果以换取性能的巨大提升。
二、算法策略概览
算法的选择直接决定了处理效率,通常需要结合存储服务进行设计。
- 基于外部排序与归并的方法:适用于静态数据集。将海量数据分片排序,然后多路归并统计频次,最后找出Top K。这高度依赖存储系统高效的分片I/O能力。
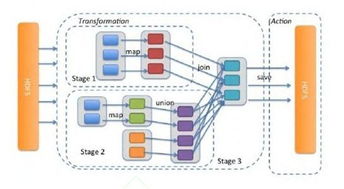
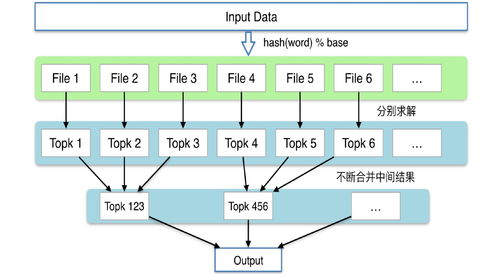
- 哈希分治与MapReduce范式:经典的海量数据处理方法。通过哈希将数据分散到多个节点(分治),每个节点计算局部频次,最后汇总产生全局Top K。这需要分布式存储(如HDFS)和计算框架(如Hadoop/Spark)的支持。
- 基于堆(Heap)的在线算法:维护一个大小为K的最小堆,用于跟踪当前遇到的高频项。通常需要结合其他数据结构(如哈希表)来快速更新计数。此方法对内存友好,但精确处理海量数据时仍需与外部存储结合。
- 近似算法:Count-Min Sketch与Lossy Counting:为了应对数据流和内存限制,常用概率数据结构。例如,Count-Min Sketch使用多个哈希函数在固定大小的二维计数阵列中累加数据,以可控的误差概率估计频次。这类算法能极大节省内存和计算资源,其状态(即Sketch矩阵)的持久化和快速访问对存储服务提出了特定需求。
三、存储支持服务的关键角色
高效解决Top K问题离不开强大的底层存储服务,其设计需考虑以下方面:
- 数据摄入层(Ingestion):
- 对于流数据,需要高吞吐、低延迟的消息队列服务(如Apache Kafka, Pulsar)来缓冲和分发数据流,供后续处理节点消费。
- 存储服务需支持高速的批量写入和追加操作。
- 中间状态存储:
- 在分布式处理中,各节点的局部统计结果(如哈希表、Sketch、部分排序结果)需要可靠的存储,以备汇总阶段读取。这要求存储服务具备高可用性和一致性(根据需求选择CP或AP)。
- 键值存储(如Redis, RocksDB, Cassandra)常用于存储键(数据项)和值(当前计数或Sketch状态)。Redis等内存数据库可提供极快的更新速度,适合高频更新的实时场景;而RocksDB等嵌入式存储引擎则提供了更经济的持久化能力。
- 持久化与查询服务:
- 最终的Top K结果或用于快速查询的完整频次索引需要被持久化。关系型数据库、文档数据库或专用的时序数据库/OLAP系统(如ClickHouse, Druid)可以胜任此角色,它们支持对预计算结果的快速聚合查询。
- 存储系统需要提供高效的随机读和范围查询能力,以支持对Top K列表的快速检索和更新。
- 架构示例:Lambda/Kappa架构的体现
- 批处理层:利用HDFS/S3存储全部原始数据或历史批次数据,使用Spark等框架进行全量计算,生成准确但延迟较高的Top K结果。
- 速度层/流处理层:使用Kafka作为数据源,由Flink, Storm等流处理引擎消费,在内存中维护近似结构(如Sketch)或增量更新结果,并将实时Top K视图写入低延迟存储(如Redis)供查询。
- 服务层:负责合并批处理结果与实时结果,或直接提供查询接口。这要求底层存储服务能够支持高并发的点查询和可能的数据合并操作。
四、技术选型与实践考量
在实践中,构建系统时需综合考量:
- 数据特性:是静态的还是流式的?数据分布的倾斜程度如何?
- 精度要求:必须100%准确,还是可以接受微小误差?
- 延迟要求:秒级、分钟级还是小时级更新?
- 资源预算:内存、CPU、存储成本的限制。
- 存储服务选型:根据一致性、持久化、延迟和吞吐需求选择组合,例如“Kafka + Flink + Redis + ClickHouse”是一种常见的组合,分别承担流缓冲、实时计算、实时状态存储和批量结果持久化与查询的角色。
###
海量数据下的最高频K项问题,是一个算法与系统工程紧密结合的典范。任何高效的算法都离不开为其量身定制的存储支持服务。从高速摄入、分布式中间状态管理到最终结果的持久化与快速服务,每一层存储组件的选择和设计都直接影响着整个系统的性能、准确性和扩展性。理解并优化这条从数据到洞察的完整链路,是应对大数据挑战的关键。